A lot of my CTF machines are made easier with the WFUZZ tool. I get a lot of questions around WFUZZ syntax. A few people also ask me for the exact command needed in some scenarios, but I feel this won’t really help people to learn unless they understand what the command is doing, and how it works. So, here is a quick article to help people out.
Put simply, WFUZZ is a web application bruteforcer. Combined with a wordlist, it can be used to scan domain names for files, or directories.
Basic Usage
$ wfuzz -w /usr/share/wordlists/dirb/big.txt http://www.target-domain-name.com/FUZZThe command here will use the big.txt wordlist, and scan the domain name, appending each word in the wordlist in place of the word ‘FUZZ’ (one by one). You will need to adjust the domain and the wordlist as required. I ran the command on my local computer, and as you can see there are loads of responses.
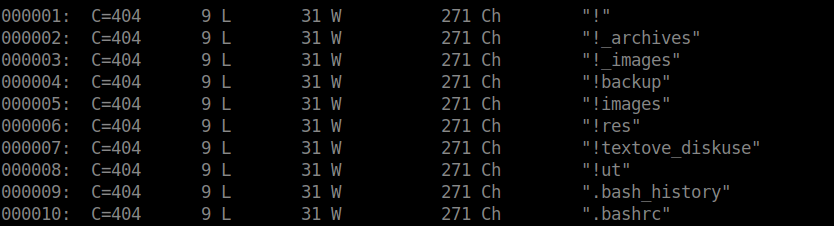
The first column shows the request number, the second column shows the response code sent by the HTTP server. In the screenshot above, none of the files scanned existed so a 404 response code was returned.
If you are not familiar with HTTP response codes, refer to this webpage.
The third column shows the amount of the lines on the web page returned. Even with ‘404 Not Found’ response codes, a web page is still returned. In my scenario, you can see it contains 9 lines:
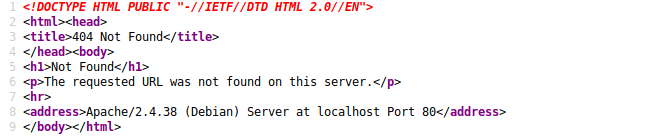
The fourth column shows the amount of words returned on the webpage. The fifth column shows the count of characters on the page returned, and the last column shows the page/request which was made.
You may be wondering why this is important? Using parameters, WFUZZ has filter functionality and it is important to understand how these filter parameters work to use them to your advantage. You can add a filter parameter to your command to exclude certain results (not include).
Filter Parameters
| Parameter | Description |
|---|---|
| –hc | Hide responses with specified response code |
| –hl | Hide responses where count of lines on response is equal to specified value |
| –hw | Hide responses where word count of web page is equal to specified value |
| –hh | Hide responses where character count of web page is equal to specified value |
Using these parameters is really easy. We just need to add them to our command. For example, if you want to exclude any 404 response codes, your command would look like this:
$ wfuzz --hc 404 -w /usr/share/wordlists/dirb/big.txt http://www.target-domain-name.com/FUZZWhen we run this command, it will show you all responses except any with a ‘404 Not Found’ response. These parameters are especially useful when enumerating sub-domains.
Enumerating Subdomains
WFUZZ is very good at enumerating sub-domains.
If you make a request to a web server to load a sub-domain, a lot of web servers are configured to return a default web page, even if the sub domain being requested does not exist.
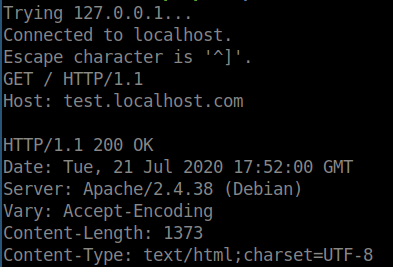
This is important to know because if we are trying to find a sub-domain, we need to find a way to exclude the ‘default’ responses to find the sub-domain we are actually interested in, else it will be very difficult to find the needle in the haystack.
To do this, we need to run the command without any filters initially. To enumerate for sub-domains, your command will look something like this:
$ wfuzz -w -H "Host: FUZZ.target-domain-name.com" /usr/share/wordlists/dirb/big.txt 127.0.0.1You will need to replace the IP address at the end of the command with the IP address of the web server you are making requests to. Similarly, you will also need to adjust the domain name as required. Syntax is very important here to be sure your command matches.
I ran a command similar to this against my local web server, and as I expected, I saw a lot of 200 response codes.
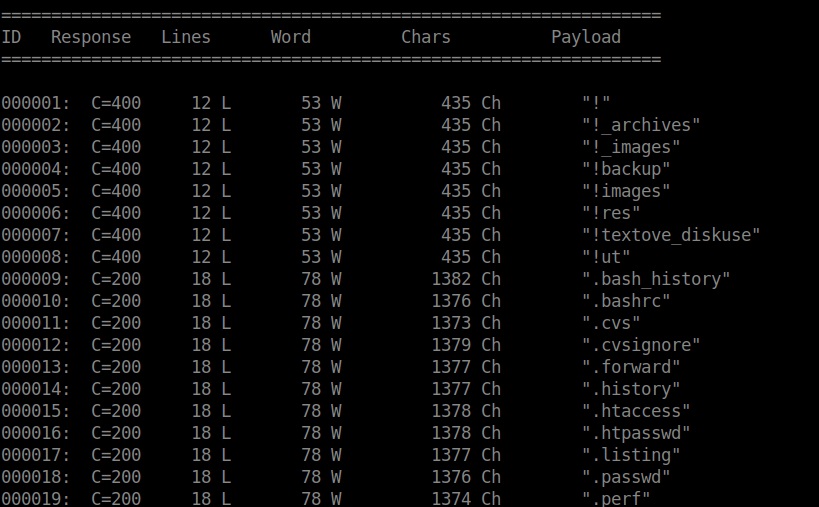
This is because, whilst these sub-domains don’t exist on the web server, the web server is still returning the default server web page. However, now that we know the word/line/character count of the default web page, we can exclude these from our results using the filters. Similarly, we probably want to exclude the 400 response codes as these will come up with most scans but aren’t necessarily useful.
$ wfuzz -w --hw 78 --hc 400 -H "Host: FUZZ.target-domain-name.com" /usr/share/wordlists/dirb/big.txt 127.0.0.1Now that we have added hw and hc parameters to our command, we are now excluding certain responses. You will not see any output until a response is detected which isn’t excluded by your filters, therefore helping you find valid and legitimate sub domain names.
Hopefully, this has helped you understand more about how WFUZZ works, but feel free to drop me more questions if needed.